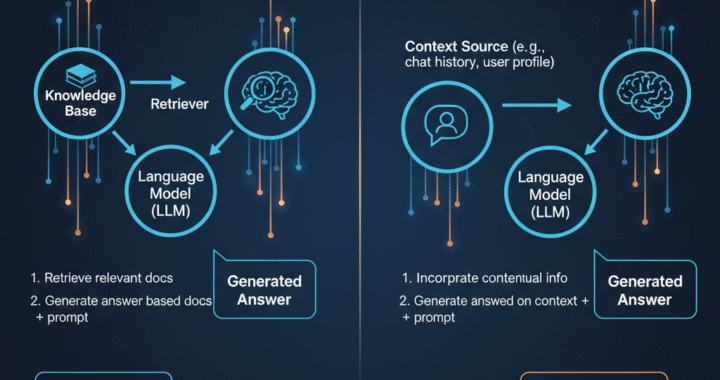
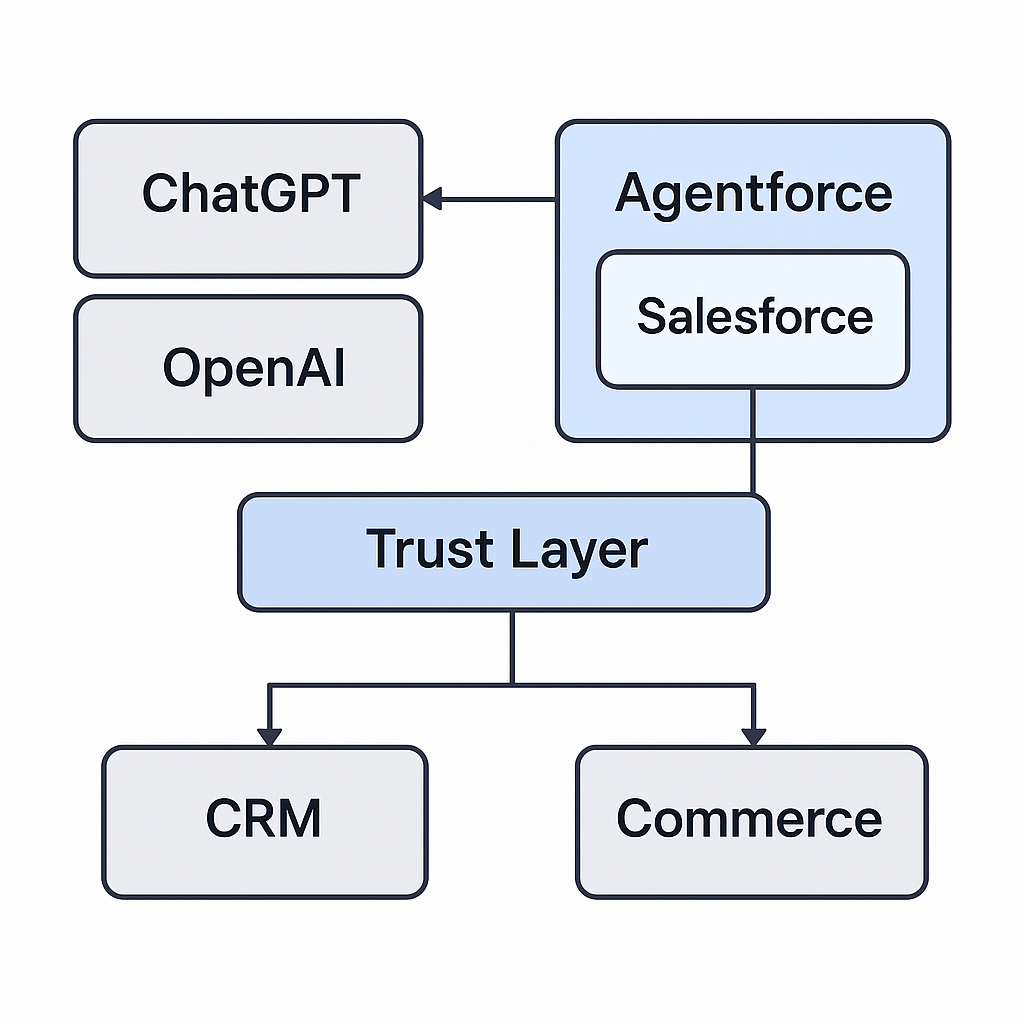
Sudipta Ghosh September 26, 2025 Fighting AI Hallucinations: Practical Strategies to Make LLMs More Reliable